Custom OData Provider for Windows Azure
16 February 2011 - Azure
Beside working on time cockpit I also do some consulting work regarding .NET in general and the Microsoft Windows Azure Platform in particular. In that context I had the chance to work as a coach in an Azure evaluation project at Austria's leading real estate search engine. Based on the research we did in this project I came up with the idea to build a custom OData provider that optimizes the way that real estate search requests are handled. It shows how sharding can be used in Winodws Azure to massively improve performance while raising costs moderately. In this blog post I would like to show you the architecture of the solution. You will see how I have built the provider and how the possibilities of the Windows Azure platform helped me to create an elastic solution that is able to handle high loads.
The Session
The content of this blog article has been presented at the conference VSOne 2011 in Munich in Feburary 2011. Here is the German and English abstract of the session:
Mit ODATA hat Microsoft ein Datenaustauschformat vorgestellt, das sich immer mehr zum Quasistandard vorarbeitet. ODATA = SOA ohne dem Overhead von SOAP. Es stehen mittlerweile Implementierungen auf verschiedenen Plattformen zur Verfügung. In dieser Session zeigt Rainer Stropek die Entwicklung individueller ODATA Provider, über die man eigene Datenstrukturen im ODATA Format zugänglich machen kann.
With ODATA Microsoft offers a data access format that has becomes an industriy standard more and more. ODATA = SOA without the overhead of SOAP. Today Microsoft and other vendors offer implementations of ODATA on various platforms. In this session Rainer Stropek demonstrates how to implement a custom ODATA provider that is tailored to specific needs.
Hands-On Lab
Preparation
-
Prerequisites:
- Visual Studio 2010
- Locally installed SQL Server 2008 R2 (Express Edition is ok)
- Windows Azure SDK 1.3 with Windows Azure Tools for Visual Studio 1.3
- Create at least three databases locally (PerfTest, PerfTest01, PerfTest02, etc.). The first one should be at least 10 GB for data and 5 GB for log; the other ones should be at least 1 GB for data and 1 GB for log.
- Create at least three databases in SQL Azure (HighVolumeServiceTest, HighVolumeServiceTest01, HighVolumeServiceTest02, etc.). The first one should be at least 10 GB; the other ones should be at least 1 GB.
-
Copy the solution CustomODataSample.sln from directory Begin into a working directory. Start Visual Studio as administrator and open the solution from there.
-
Adjust connection settings in the following config files according to your specific setup (see above):
- CustomODataService/Web.config
- CustomODataProvider.Test/App.config
- DemoDataGenerator/App.config
- CustomODataService.Cloud/ServiceConfiguration.cscfg
-
Use the sample tool DemoDataGenerator to fill your databases (local and cloud) with demo data. With these two T-SQL statements you can check the number of rows and the size of your demo databases:
select count(*) from dbo.RealEstate SELECT SUM(reserved_page_count)*8.0/1024 + SUM(lob_reserved_page_count)*8.0/1024 FROM sys.dm_db_partition_statsYour large demo database in the cloud should contain approx. 12.4 million rows.
Add Default OData Service
-
Add a WCF Data Service to the service project CustomODataService:
-
Select Add new item/WCF Data Service and call it DefaultRealEstateService.
-
This is how the implementation should look like:
using System.Data.Services; using System.Data.Services.Common; using System.ServiceModel; using CustomODataService.Data; namespace CustomODataService { [ServiceBehavior(IncludeExceptionDetailInFaults = true)] public class DefaultRealEstateService : DataService<RealEstateEntities> { public static void InitializeService(DataServiceConfiguration config) { config.SetEntitySetAccessRule("*", EntitySetRights.AllRead); config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2; } } protected override RealEstateEntities CreateDataSource() { return RealEstateEntities.Create(); } } -
Right-click DefaultRealEstateService.svc and select View in browser. You should see the list of resource types that the service support (RealEstate). Now try to do a query using e.g. the following URL: http://localhost:<YourPort>/DefaultRealEstateService.svc/RealEstate?$top=25&$filter=SizeOfParcel ge 200 and SizeOfParcel lt 1000 and HasBalcony eq true&$orderby=SizeOfBuildingArea desc.
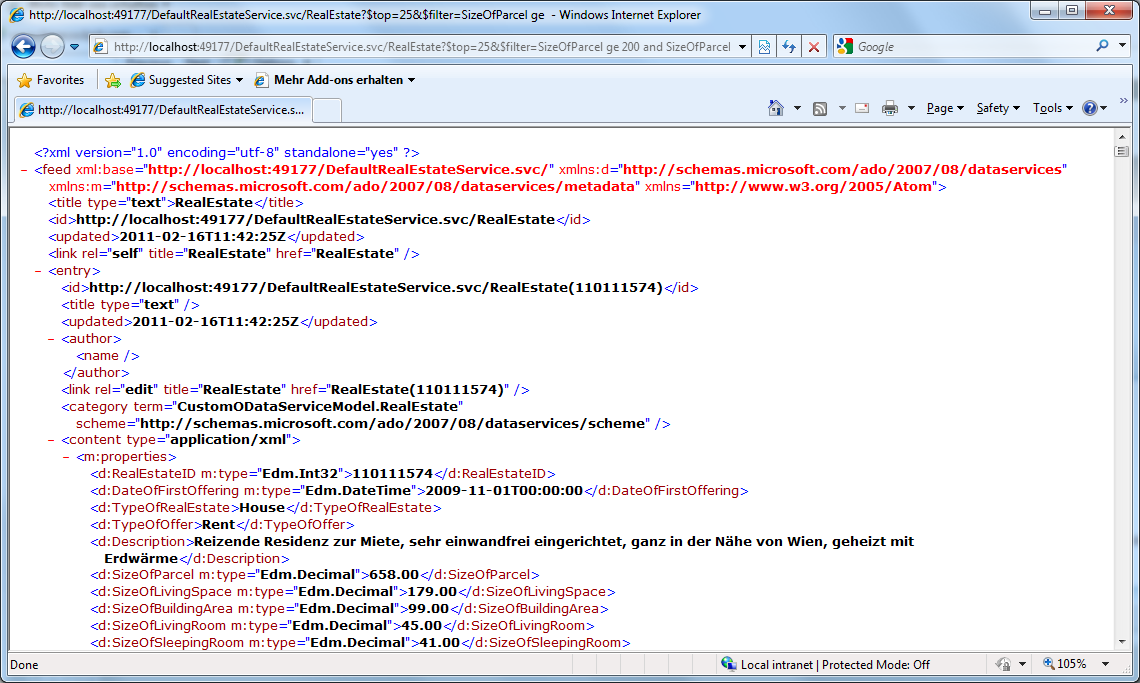
Try the same for your local database and for your cloud database (change connection strings in your config files).
-
Add Custom Provider
-
The first step to create a custom OData service is to implement a custom context object. The sample solution contains a base class that makes it easier to implement such a context object: CustomDataServiceContext. In the session I have discussed this base class in more details (see also slide deck; link at the beginning of this article). This is how the implementation could look like (notice that the only job of the context object is to provide a queryable that the OData service can operate on):
using System; using System.Data.Services.Providers; using System.Linq; using CustomODataService.CustomDataServiceBase; using CustomODataService.Data; namespace CustomODataService { public class RealEstateContext : CustomDataServiceContext { static RealEstateContext() { } public override IQueryable GetQueryable(ResourceSet set) { if (set.Name == "RealEstate") { return RealEstateEntities.Create().RealEstate; } throw new NotSupportedException(string.Format("{0} not found", set.Name)); } } } -
The second step is the creation of the custom provider. The sample solution contains a base class that makes it easier to implement the custom provider: CustomDataService<T>. In the session I have discussed this base class in more details (see also slide deck; link at the beginning of this article). This is how the implementation could look like:
using System; using System.Data.Services; using System.Data.Services.Common; using System.Data.Services.Providers; using System.ServiceModel; using CustomODataService.CustomDataServiceBase; using CustomODataService.Data; namespace CustomODataService { [ServiceBehavior(IncludeExceptionDetailInFaults = true)] public class CustomRealEstateDataService : CustomDataService<RealEstateContext> { public static void InitializeService(DataServiceConfiguration config) { config.SetEntitySetAccessRule("*", EntitySetRights.AllRead); config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2; } public override IDataServiceMetadataProvider GetMetadataProvider(Type dataSourceType) { return BuildMetadataForEntityFrameworkEntity<RealEstate>("Namespace"); } public override IDataServiceQueryProvider GetQueryProvider(IDataServiceMetadataProvider metadata) { return new CustomDataServiceProvider<RealEstateContext>(metadata); } protected override RealEstateContext CreateDataSource() { return new RealEstateContext(); } } }As you can see the custom provider metadata is built using the helper function BuildMetadataForEntityFrameworkEntity<T>. This function uses reflection to inspect the given type and generates all the necessary OData resource sets and types. In practise you could add addition intelligence here (e.g. provide different metadata for different use cases, generate metadata manually if you do not implement a stronly typed provider).
/// <summary> /// Helper function that generates service metadata for entity framework entities based on reflection /// </summary> /// <typeparam name="TEntity">Entity framework entity type</typeparam> /// <param name="namespaceName">Name of the namespace to which the entity type should be assigned</param> public static IDataServiceMetadataProvider BuildMetadataForEntityFrameworkEntity<TEntity>(string namespaceName) { var productType = new ResourceType( typeof(TEntity), ResourceTypeKind.EntityType, null, // BaseType namespaceName, // Namespace typeof(TEntity).Name, false // Abstract? ); // use reflection to get all properties (except entity framework specific ones) typeof(TEntity) .GetProperties(BindingFlags.Public | BindingFlags.Instance) .Where(pi => pi.DeclaringType == typeof(TEntity)) .Select(pi => new ResourceProperty( pi.Name, (Attribute.GetCustomAttributes(pi).OfType<EdmScalarPropertyAttribute>().Where(ea => ea.EntityKeyProperty).Count() == 1) ? ResourcePropertyKind.Primitive | ResourcePropertyKind.Key : ResourcePropertyKind.Primitive, ResourceType.GetPrimitiveResourceType(pi.PropertyType))) .ToList() .ForEach(prop => productType.AddProperty(prop)); var metadata = new CustomDataServiceMetadataProvider(); metadata.AddResourceType(productType); metadata.AddResourceSet(new ResourceSet(typeof(TEntity).Name, productType)); return metadata; }
Is that it? We have created a custom read-only provider and we could add additional features like ability to write, support for relations, etc. If you are interested in these things I recommend reading this excellent blog post series: Custom Data Service Providers by Alex James, a Program Manager working on the Data Services team at Microsoft. I will not repeat his descriptions here. As described in the slides (see top of this blog article) my goal is to create a custom implementation to IQueryable and use it in the OData service. The IQueryable implemenation should hide all the complexity of sharding.
Performance Evaluation
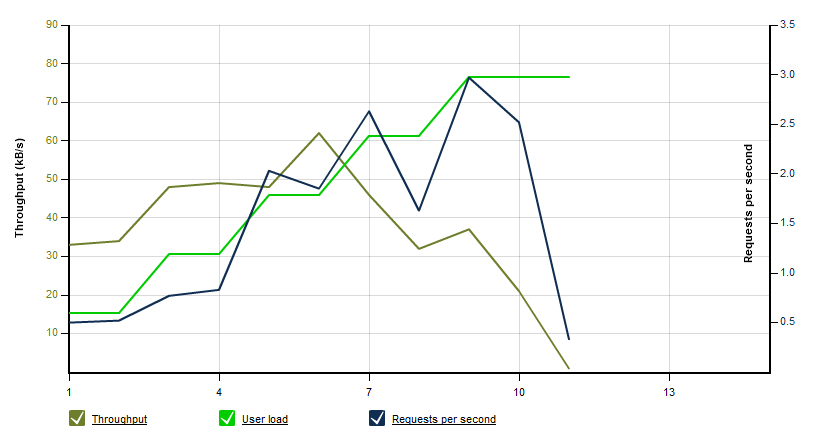
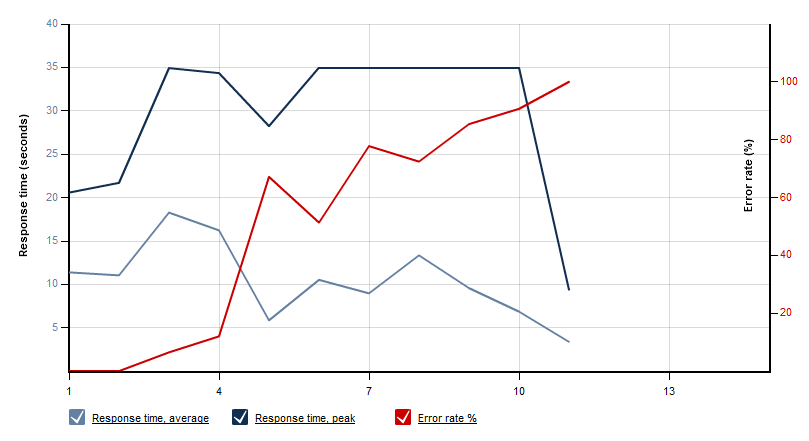
In order to see how the implemented OData providers perform I used LoadStorm to simulate some loads. I defined three reference queries and let 10 to 50 concurrent users (step-up load testing scenario; each of them firing six queries per minute) do some queries. The result has been as expected: Because of the large database on the single SQL Azure server the solution does not really scale. The first chart shows the number of users and the throughput. In the second chart you can see that from a certain number of concurrent users the response time gets greater then 35 seconds; as a result we see a lot of HTTP errors.

The poor performance does not come from OData. I also created a unit test that runs a Linq-to-Entities query - same results:
[TestMethod]
public void TestLocalQuery()
{
using (var context = RealEstateEntities.Create())
{
var result = context.RealEstate.Take(25).Where(re => re.Location == "Wien" && re.HasBalcony.Value).OrderBy(re => re.SizeOfGarden).ToArray();
}
}Custom LINQ Provider - First Steps
If you want to implement IQueryable you should really consider using the IQToolkit. If offers a base class QueryProvider. You can derive your custom IQueryable from that class. In our case we will implement the class ShardingProvider. It should be able to send a single Linq-to-Entities query to mulitple database in parallel and consolidate the partly results after that. The declaration of our new class looks like this:
public class ShardingProvider<TContext, TEntity>
: QueryProvider
where TContext : ObjectContext
where TEntity : EntityObject
{
private ContextCreatorDelegate ContextCreator { get; set; }
private EntityProviderDelegate EntityProvider { get; set; }
private string[] ConnectionStrings { get; set; }
public delegate TContext ContextCreatorDelegate(string connectionString);
public delegate IQueryable<TEntity> EntityProviderDelegate(TContext context);
public ShardingProvider(ContextCreatorDelegate contextCreator, EntityProviderDelegate entityProvider, params string[] connectionStrings)
{
if (contextCreator == null)
{
throw new ArgumentNullException("contextCreator");
}
if (entityProvider == null)
{
throw new ArgumentNullException("entityProvider");
}
if (connectionStrings == null)
{
throw new ArgumentNullException("connectionStrings");
}
this.ContextCreator = contextCreator;
this.EntityProvider = entityProvider;
this.ConnectionStrings = connectionStrings;
}
public override object Execute(Expression expression)
{
throw new NotImplementedException();
}
public override string GetQueryText(Expression expression)
{
throw new NotImplementedException();
}
}To try our custom LINQ provider we can add a second unit test. This time the target queryable is Query<T> (part of IQToolkit). Query<T> needs a Linq provider - our custom ShardingProvider. As you can see the LINQ query to Entity Framework and to our sharding provider are identical. The only additional code that is necessary is the code for building the connection strings to our sharding databases. Here is the code you have to add to LinqProviderTest.cs in order to be able to try the custom LINQ provider:
[TestMethod]
public void TestMethod2()
{
var queryable = CreateQueryableRoot();
var result = queryable.Take(25).Where(re => re.Location == "Wien" && re.HasBalcony.Value).OrderBy(re => re.SizeOfGarden).ToArray();
}
private static Query<RealEstate> CreateQueryableRoot()
{
string shardingConnectingString = ConfigurationManager.AppSettings["ShardingDatabaseConnection"];
int numberOfShardingDatabases = Int32.Parse(ConfigurationManager.AppSettings["NumberOfShardingDatabases"]);
var connectionStrings = Enumerable.Range(1, numberOfShardingDatabases)
.Select(i => string.Format(shardingConnectingString, i))
.ToArray();
var queryable = new Query<RealEstate>(
new ShardingProvider<RealEstateEntities, RealEstate>(
(s) => new RealEstateEntities(new EntityConnectionStringBuilder()
{
Metadata = "res://*/RealEstateModel.csdl|res://*/RealEstateModel.ssdl|res://*/RealEstateModel.msl",
Provider = "System.Data.SqlClient",
ProviderConnectionString = s
}.ConnectionString),
(ctx) => ctx.RealEstate,
connectionStrings.ToArray()));
return queryable;
}Before we finish our Linq provider we want to link our custom OData service with the custom Linq provider. The only thing we have to do to achieve this is to use the code shown above (creates Query<T> instance) with the existing RealEstateContext. Here is the new code for RealEstateContext.cs (notice that GetQueryable now returns Query<T>):
using System;
using System.Configuration;
using System.Data.EntityClient;
using System.Data.Services.Providers;
using System.Linq;
using CustomODataService.CustomDataServiceBase;
using CustomODataService.Data;
using IQToolkit;
using Microsoft.WindowsAzure.ServiceRuntime;
using ShardingProvider;
namespace CustomODataService
{
public class RealEstateContext : CustomDataServiceContext
{
private static int numberOfShardingDatabases = 10;
static RealEstateContext()
{
if (RoleEnvironment.IsAvailable)
{
numberOfShardingDatabases = Int32.Parse(RoleEnvironment.GetConfigurationSettingValue("NumberOfShardingDatabases"));
}
else
{
numberOfShardingDatabases = Int32.Parse(ConfigurationManager.AppSettings["NumberOfShardingDatabases"]);
}
}
public override IQueryable GetQueryable(ResourceSet set)
{
if (set.Name == "RealEstate")
{
return CreateQueryable();
}
throw new NotSupportedException(string.Format("{0} not found", set.Name));
}
protected static IQueryable<RealEstate> CreateQueryable()
{
string shardingConnectingString;
if (RoleEnvironment.IsAvailable)
{
shardingConnectingString = RoleEnvironment.GetConfigurationSettingValue("ShardingDatabaseConnection");
}
else
{
shardingConnectingString = ConfigurationManager.AppSettings["ShardingDatabaseConnection"];
}
var connectionStrings = Enumerable.Range(1, numberOfShardingDatabases)
.Select(i => string.Format(shardingConnectingString, i))
.ToArray();
return new Query<RealEstate>(new ShardingProvider<RealEstateEntities, RealEstate>(
(s) => new RealEstateEntities(new EntityConnectionStringBuilder()
{
Metadata = "res://*/RealEstateModel.csdl|res://*/RealEstateModel.ssdl|res://*/RealEstateModel.msl",
Provider = "System.Data.SqlClient",
ProviderConnectionString = s
}.ConnectionString),
(context) => context.RealEstate,
connectionStrings.ToArray()));
}
}
}You want to see it work? Set a break point to ShardingProvider.Execute and run an OData query against CustomRealEstateDataService.svc. You will see the query's expression tree received by the execute method. The following two images show this. The first one shows the query in the browser. The second one shows the resulting expression tree in the Linq provider.

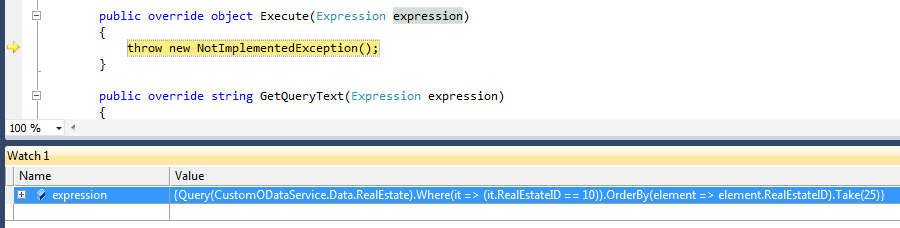
Implementing The Custom LINQ Provider
The implementation of the custom LINQ provider has to perform the following two steps:
- Make sure that the query is ok (e.g. must be sorted, must contain top-clause, etc.; business rules defined by the customer in the project mentioned at the beginning of this blog article)
- Parallel loop over all connections to sharding databases
- Open entity framework connection to sharding database
- Replace Query<T> in expression tree by connection to sharding database
- Execute query and return partial result
- Combine partial results by sorting them and applying the top-clause
Here is the implementation of the ShardingProvider class that does this (notice that I do not include the visitor classes here; they are in the sample code download):
using System;
using System.Collections.Generic;
using System.Data.Objects;
using System.Data.Objects.DataClasses;
using System.Linq;
using System.Linq.Expressions;
using System.Reflection;
using System.Threading;
using IQToolkit;
namespace ShardingProvider
{
/// <summary>
/// Implements a query provider that takes a query (i.e. an expression tree) using Entity Framework and sends it
/// to multiple underlying databases in parallel (sharding).
/// </summary>
/// <typeparam name="TContext">Entity Framework object context type</typeparam>
/// <typeparam name="TEntity">Entity framework entity type</typeparam>
public class ShardingProvider<TContext, TEntity>
: QueryProvider
where TContext : ObjectContext
where TEntity : EntityObject
{
private ContextCreatorDelegate ContextCreator { get; set; }
private EntityProviderDelegate EntityProvider { get; set; }
private string[] ConnectionStrings { get; set; }
private static PropertyInfo KeyProperty { get; set; }
/// <summary>
/// Looks up the key property of the underlying entity framework entity type
/// </summary>
static ShardingProvider()
{
var keyProperties = typeof(TEntity)
.GetProperties()
.Where(p => Attribute
.GetCustomAttributes(p)
.OfType<EdmScalarPropertyAttribute>()
.Where(ea => ea.EntityKeyProperty)
.Count() == 1)
.ToArray();
if (keyProperties.Count() != 1)
{
throw new ArgumentException("TEntity has to have a key consisting of a single property (EdmScalarPropertyAttribute.EntityKeyProperty)", "TEntity");
}
KeyProperty = keyProperties.First();
}
public delegate TContext ContextCreatorDelegate(string connectionString);
public delegate IQueryable<TEntity> EntityProviderDelegate(TContext context);
/// <summary>
/// Initializes a new instance of the ShardingProvider class
/// </summary>
/// <param name="contextCreator">Function that can be used to create an underlying entity framework context object</param>
/// <param name="entityProvider">Function that returns the IQueryable from the underlying entity framework context object</param>
/// <param name="connectionStrings">SQL connection string to sharding databases</param>
public ShardingProvider(ContextCreatorDelegate contextCreator, EntityProviderDelegate entityProvider, params string[] connectionStrings)
{
if (contextCreator == null)
{
throw new ArgumentNullException("contextCreator");
}
if (entityProvider == null)
{
throw new ArgumentNullException("entityProvider");
}
if (connectionStrings == null)
{
throw new ArgumentNullException("connectionStrings");
}
this.ContextCreator = contextCreator;
this.EntityProvider = entityProvider;
this.ConnectionStrings = connectionStrings;
}
public override object Execute(Expression expression)
{
var verifyer = new VerifyingVistor<TEntity>();
var methodInfoExpr = verifyer.Visit(expression) as MethodCallExpression;
if (!verifyer.IsValid)
{
throw new ShardingProviderException("Linq query is not valid");
}
// Send query to all sharding databases in parallel
var result = this.ConnectionStrings
.AsParallel()
.WithDegreeOfParallelism(this.ConnectionStrings.Length)
.SelectMany(connectionString =>
{
using (var context = this.ContextCreator(connectionString))
{
context.CommandTimeout = 300;
var rewriter = new SwitchQueryable<TEntity>(Expression.Constant(this.EntityProvider(context)));
var ex2 =
Expression.Lambda<Func<IEnumerable<TEntity>>>(
Expression.Call(
methodInfoExpr.Method,
rewriter.Visit(methodInfoExpr.Arguments[0]),
methodInfoExpr.Arguments[1]));
return ex2.Compile()().ToArray();
}
})
.ToArray();
// Combine partial results by ordering them and applying top operator
ParameterExpression param2;
Expression<Func<IEnumerable<TEntity>>> ex3;
return (ex3 = Expression.Lambda<Func<IEnumerable<TEntity>>>(
Expression.Call(
typeof(Enumerable),
"Take",
new[] { typeof(TEntity) },
Expression.Call(
typeof(Enumerable),
"ThenBy",
new[] { typeof(TEntity), KeyProperty.PropertyType },
Expression.Call(
typeof(Enumerable),
verifyer.Ascending ? "OrderBy" : "OrderByDescending",
new[] { typeof(TEntity), ((PropertyInfo)verifyer.OrderByLambdaBody.Member).PropertyType },
Expression.Constant(result),
verifyer.OrderByLambda),
Expression.Lambda(
Expression.MakeMemberAccess(
param2 = Expression.Parameter(typeof(TEntity), "src"),
KeyProperty),
param2)),
verifyer.TakeExpression)))
.Compile()().ToArray();
}
public override string GetQueryText(Expression expression)
{
throw new NotImplementedException();
}
}
}Tip: Don't forget to set minimum threads in thread pools to enable full potential of PLINQ with async database IO
static CustomRealEstateDataService()
{
int minThreads, completionPortThreads;
ThreadPool.GetMinThreads(out minThreads, out completionPortThreads);
ThreadPool.SetMinThreads(
Math.Max(minThreads, 11),
Math.Max(completionPortThreads, 11));
}Performance Evaluation
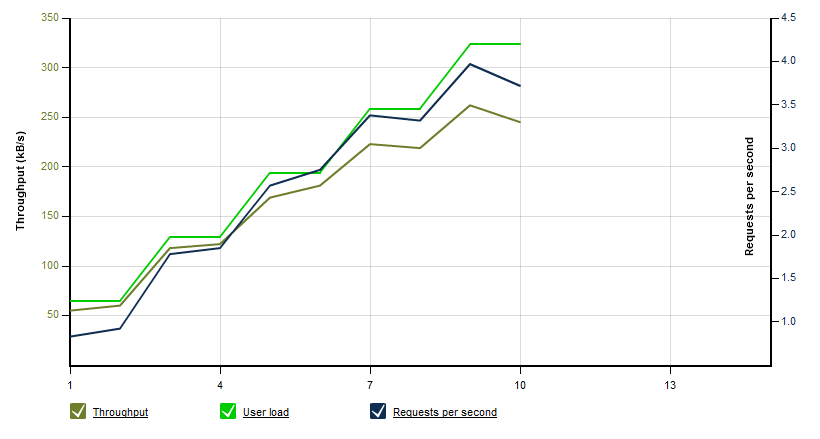
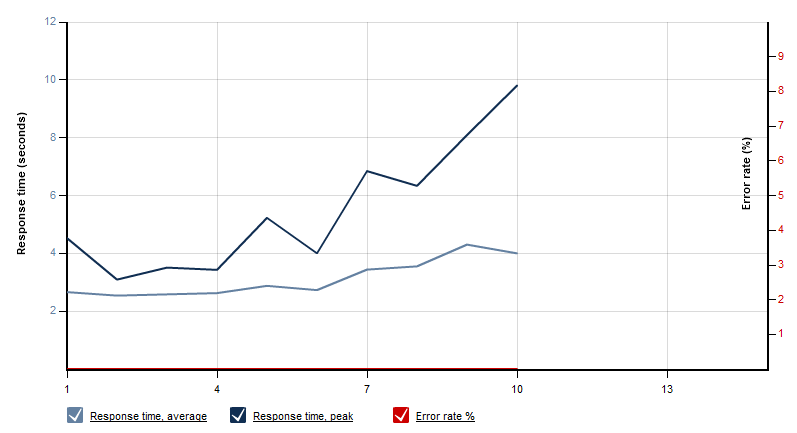
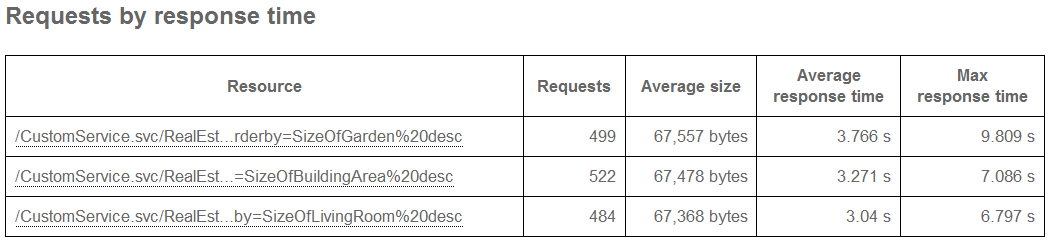
Now that our sharding provider is completely implemented I used LoadStorm again to simulate the same load as shown before with the standard OData provider.The results look very different - of course. No errors and an average response time of approx. 3 seconds instead of more than 10 :-)
Content



