Deep Dive into C# 7 - Part II
23 May 2017 - C#, CSharp, Roslyn

Introduction
Recently, I have been doing some conference sessions about C# 7. My next talk in that series will be at Techorama in Belgium tomorrow. In this blog post I summarize the talk and share the samples I will do.
Here is the abstract of my Techorama-session: Let’s spend one hour on C# 7 and discover the new language features. Rainer Stropek, long-time Azure MVP and Regional Director, will show you no slides in this session. Instead, you will see 60 minutes of live demos with practical examples for C#’s new syntax constructs and have lots of fun with dnSpy and profilers to look under the covers of C# 7.
Note that this blog post contains some larger images. You can click on them to enlarge.
Video
Expression-Bodied Members
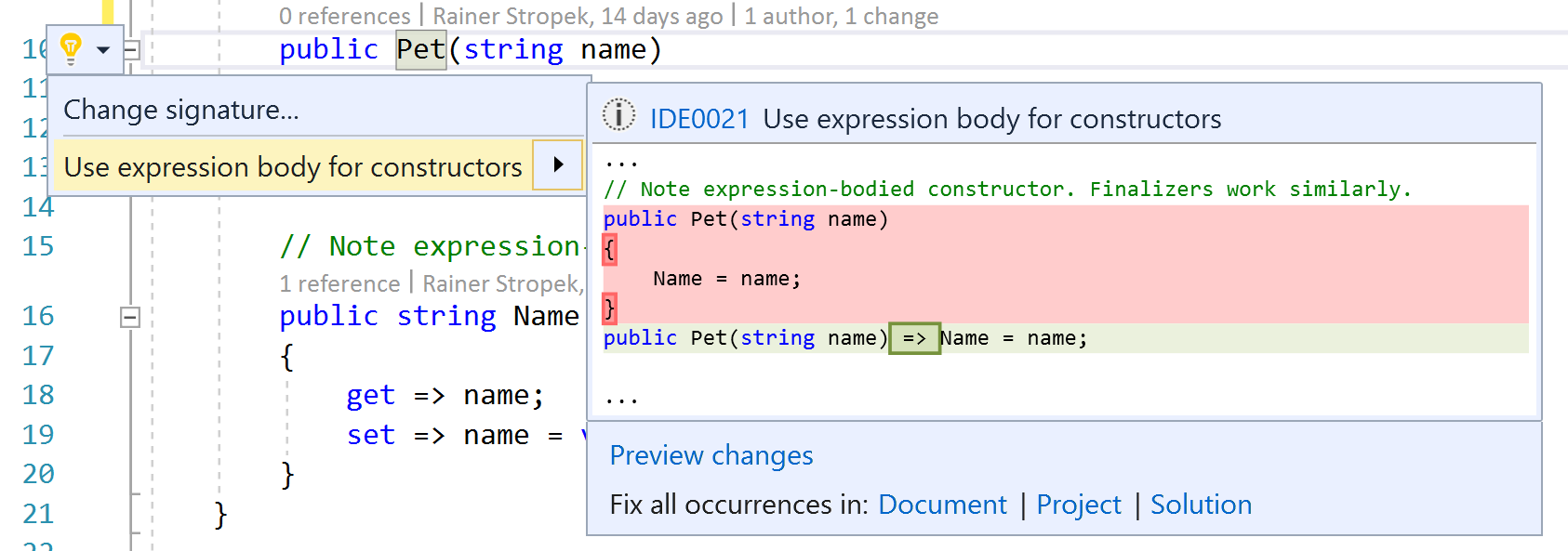
Let’s start with something simple. Do you like expression-bodied members? Good news, C# now supports this syntax for additional members like constructors, finalizers, etc.
Note that Visual Studio has refactorings built-in to turn block-bodied into expression-bodied members and vice versa.
I want to take this opportunity and introduce you to a tool I will be using throughout this session:
dnSpy. It is ildasm on steroids. The tool is open source and free.
With dnSpy, we take a look at what the compiler does behind the scenes with expression-bodied members. It turns out that it is just some syntactic sugar. This new syntax is converted to conventional C#/IL behind the scenes. Here is a screenshot demonstrating the point. I also added another new feature of C# 7: Throw Expressions. Again, it is just some new syntactic sugar.

Local Functions
Introduction
Let’s switch gears and look at a more fundamental change to the C# programming language: Local functions. Until recently, you had to use delegates and lambdas if you wanted a function that can only be called inside another function. You wonder why anybody would want a local function? Couldn’t you just create a private function in your class? Well,…
- …maybe the local function depends on some initialization code that is just present in the enclosing function.
- …maybe the local function has a strong logical connection to the enclosing functions and you don’t want to separate them to keep your code readable.
- …maybe the local function needs a lot of state from the enclosing function and you don’t want to pass it. With local function, you can access all variables of the enclosing functions.
Basic Example
Here is a simple example of a local function implemented as a lambda:
static void BasicLocalFunction()
{
MathOp add = (x, y) => x + y;
Console.WriteLine($"The result is {add(1, 2)}\n");
}
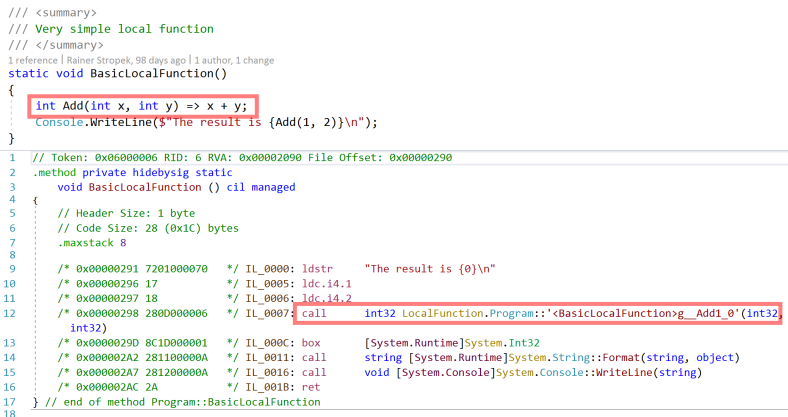
This is what the same code looks like with C# 7’s new local functions feature:
static void BasicLocalFunction()
{
int Add(int x, int y) => x + y;
Console.WriteLine($"The result is {Add(1, 2)}\n");
}
Not much difference, right? If we look behind the scenes, there is a huge difference. Let’s look at the IL code produced by the lambda-version first.
- Note the
newobjoperation for the delegate in line 20. - Note that the local function is called with a
callvirt.
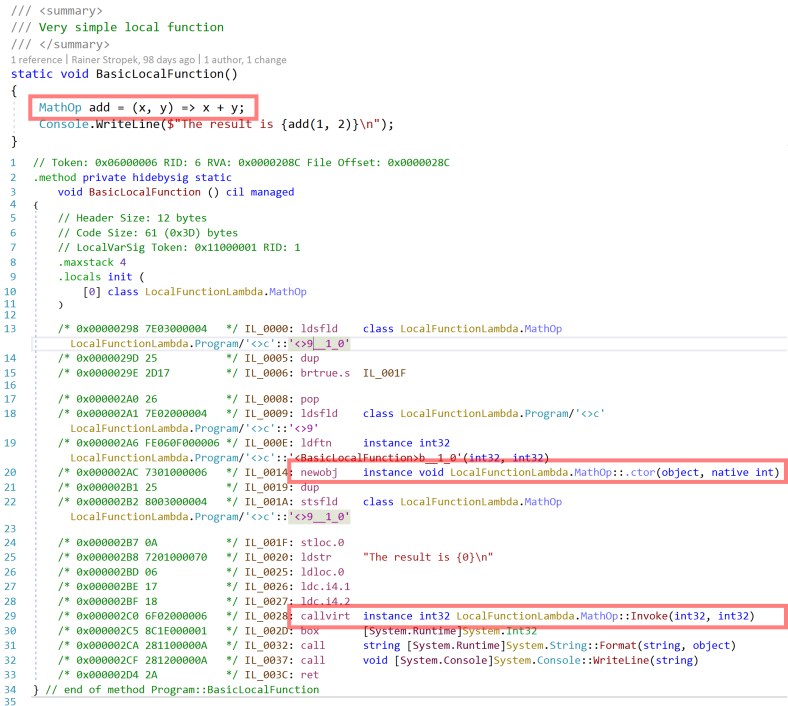
Compare that to the version with C# now supporting local functions natively. The IL code is much shorter. There is no allocation and no virtual function call. Nice, isn’t it?
Closure
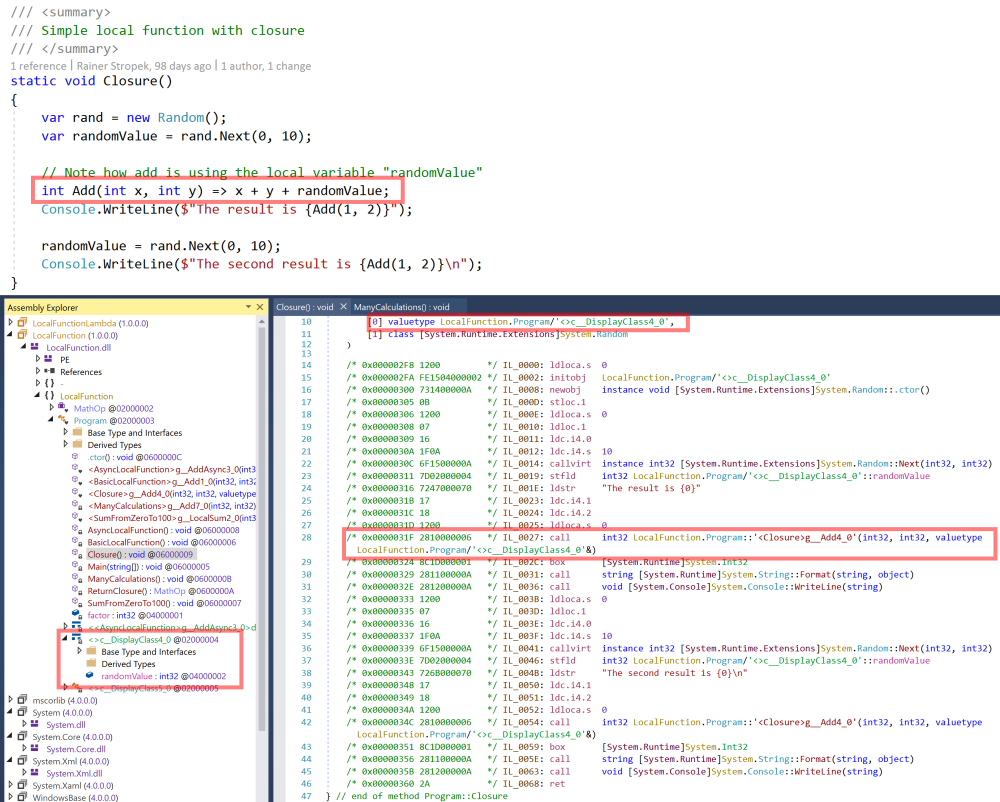
If we add a reference to a variable of the enclosing function, the differences become even more obvious. Let’s again start with an implementation using a lambda. Note that add references the variable randomValue of the enclosing function.
- The local function with the variable reference becomes a separate class (
<>c__DisplayClass3_0). - Therefore, a memory allocation (line 14) is necessary.
- Like in the basic sample, we have a virtual method call (line 31).
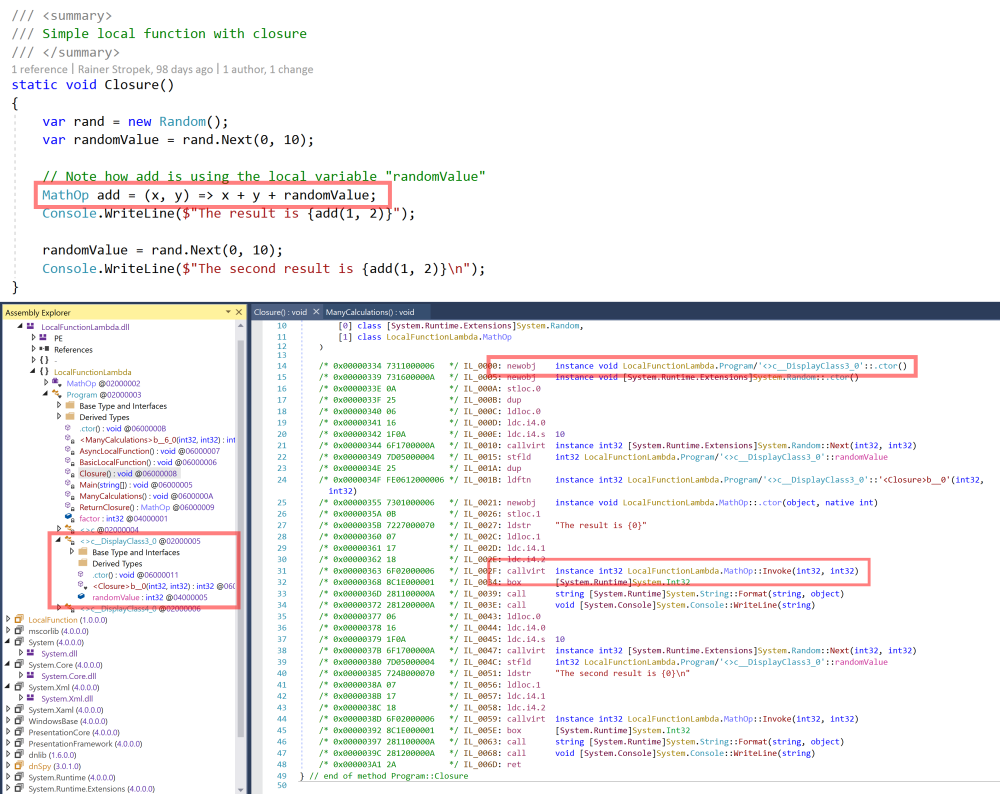
If we change the code to local functions, the uglyness goes away.
- Instead of a compiler-generated class, we now get a value type (
<>c__DisplayClass4_0). - No
newobj, just a local variable (line 10). - No virtual method call anymore (line 28).
What’s the Problem?
So we have seen that local functions do generate much nicer IL code. But does it really make a difference? If you do a lot of local function calls, it definitely does. Let me show you what I mean.
I created another test method with a local function (add). Here is the implementation using a lambda. The code with a real C# local function looks nearly the same (look at it on GitHub). As you can see, the function will do some dummy calculations involving the local function for ten seconds.
void ManyCalculations()
{
const int seconds = 10;
var rand = new Random();
var watch = new Stopwatch();
var counter = 0L;
Console.WriteLine($"Calculating for {seconds} seconds...");
watch.Start();
while (watch.Elapsed < TimeSpan.FromSeconds(seconds))
{
// Note that add uses "factor"
MathOp add = (x, y) => x + y + factor;
var result = add(rand.Next(0, 100), rand.Next(0, 100));
counter++;
}
Console.WriteLine($"Done {counter} calculations");
}
As expected, we find an allocation for the delegate in the IL-code of the lambda-version:

The version with the native C# local function does not need to allocate memory on the heap:

I ran both versions for you and gathered performance data using the awesome tool PerfView. PerfView counts the garbage collections and gives us a nice summary at the end. Here are the results of both runs:
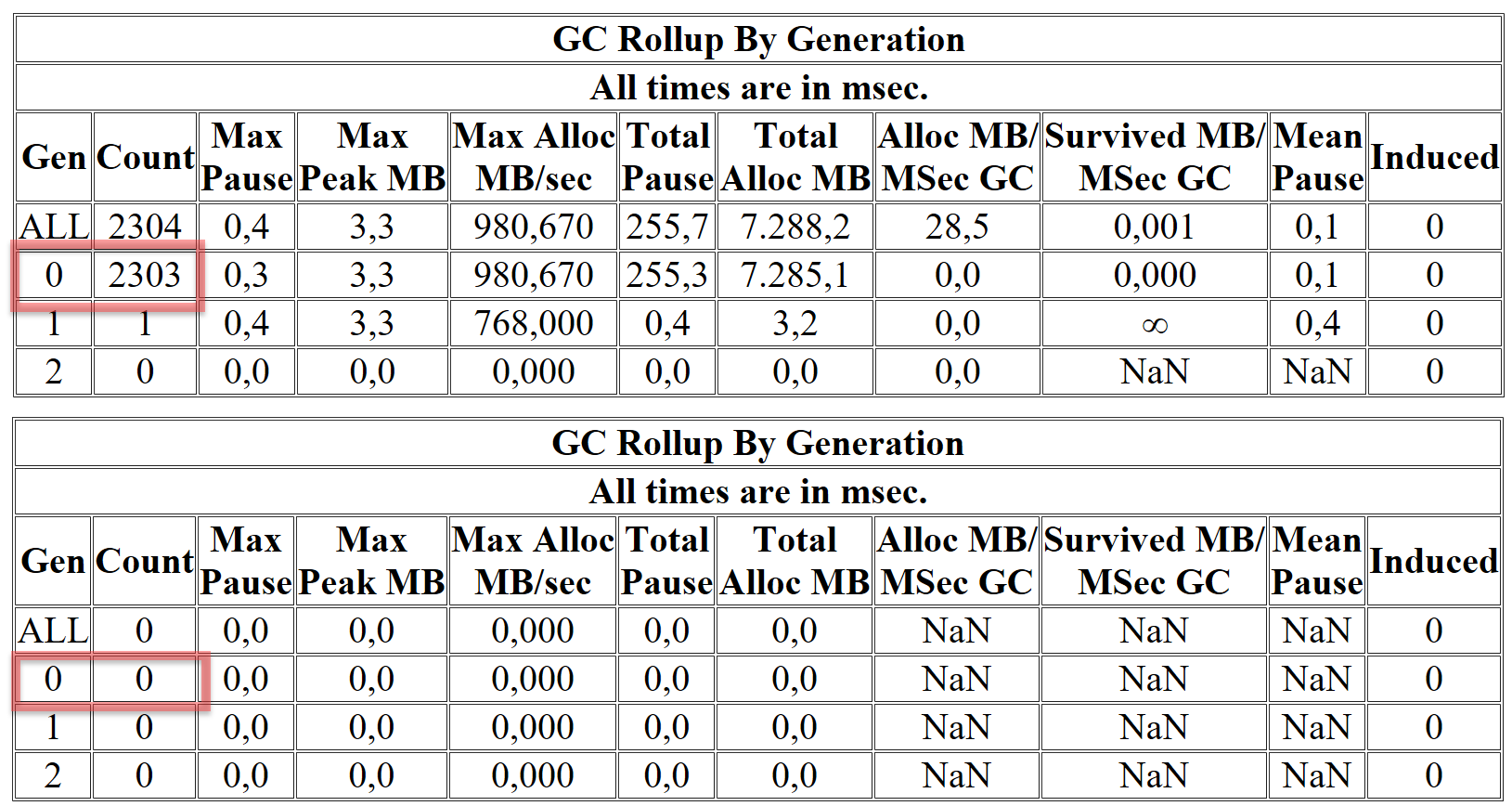
More than 2000 GC runs compared to zero. That is a difference.
out var
Let’s relax a bit and look at another simple but handy extension that C# 7 brought: The possibility to add a variable declaration right into a function call with an out parameter. The following code compares classic and new C# code:
static void Classic(string numberAsString)
{
int number;
if (int.TryParse(numberAsString, out number))
{
Console.WriteLine($"Ok, I got the number {number}");
}
else
{
Console.WriteLine("Sorry, this is not a number");
}
}
static void CSharpSeven(string numberAsString)
{
if (int.TryParse(numberAsString, out var number))
{
Console.WriteLine($"Ok, I got the number {number}");
}
else
{
Console.WriteLine("Sorry, this is not a number");
}
}
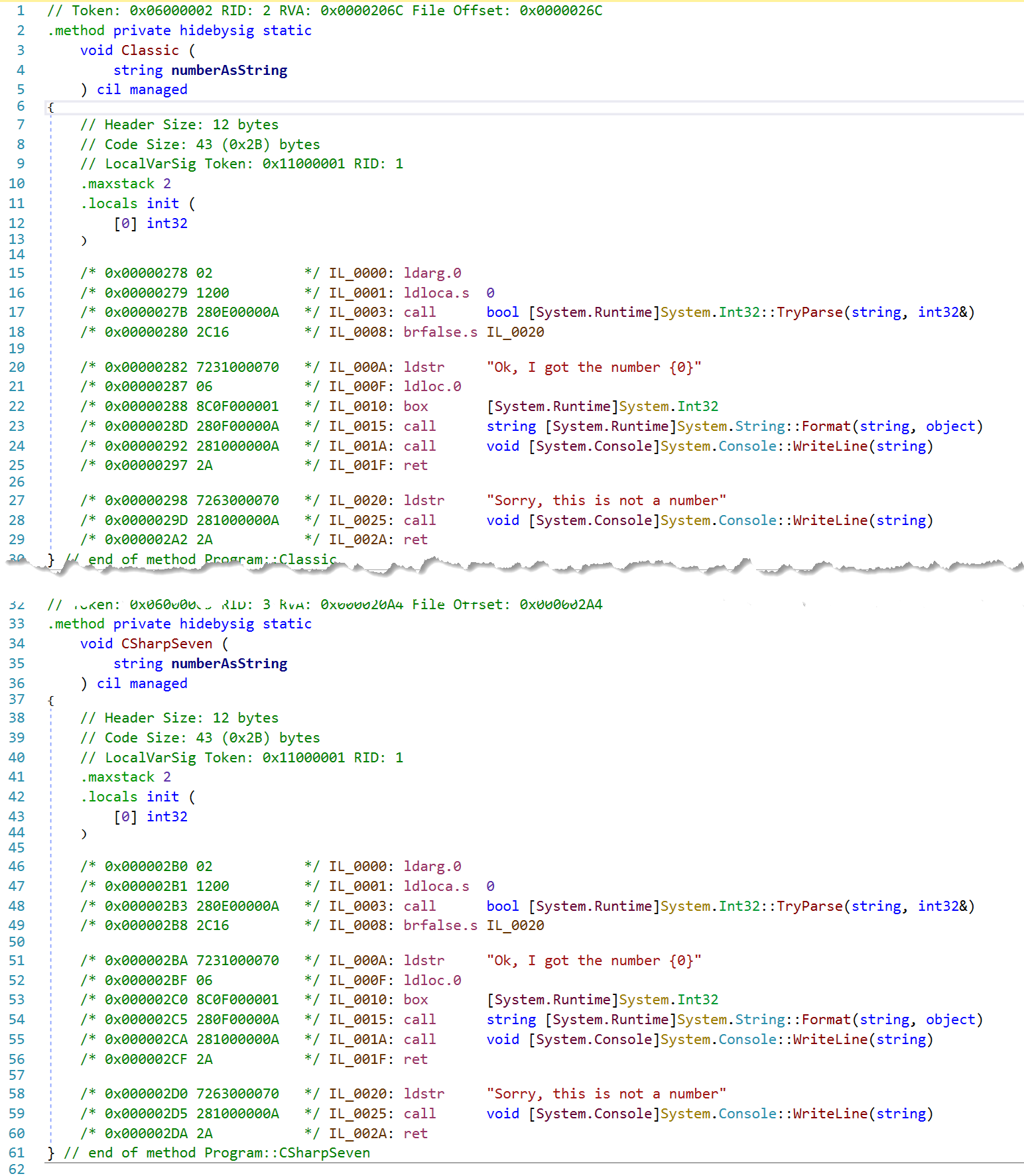
What happens behind the scenes? Does the new syntax make a profound difference or is it again just some new syntactic sugar? The latter is true. The following screenshot compares the IL generated from both methods shown above. As you can see, they lead to identical IL code.
Note that you can combine out with _ now to indicate that you are not interested in the specific result.
Here is an example demonstrating what I mean:
static void ReturnSomeNumbers(out int val1, out int val2, out int val3)
=> val1 = val2 = val3 = 42;
static void ConsumeSomeNumbers()
{
ReturnSomeNumbers(out var val, out _, out _);
Console.WriteLine(val);
}
Do you think it makes a difference on the IL-level whether you use _ instead of a variable name like dummy? Check it in dnSpy and you will see that it doesn’t make any difference. The same IL code would be generated.
Pattern Matching
The Basics
Time to look at another major extension of C#: Pattern Matching. Here is a simple example to get started. It checks whether an object is a string in the classic way and in C# 7 style:
void CheckClassic(object obj)
{
// In the past we would have written...
var name = obj as string;
if (name != null)
{
Console.WriteLine($"o is a string with value {name}");
}
}
void CheckCSharpSeven(object obj)
{
// Now we can be much more concise using a "Type Pattern":
if (obj is string name)
{
// Now we have a local variable `name` of type `string`
Console.WriteLine($"o is a string with value {name}");
}
}
We can use Roslyn’s Syntax Visualizer to compare the syntax tree of both versions. Here is the classic one. No surprises, just an IfStatement with a BinaryExpression.
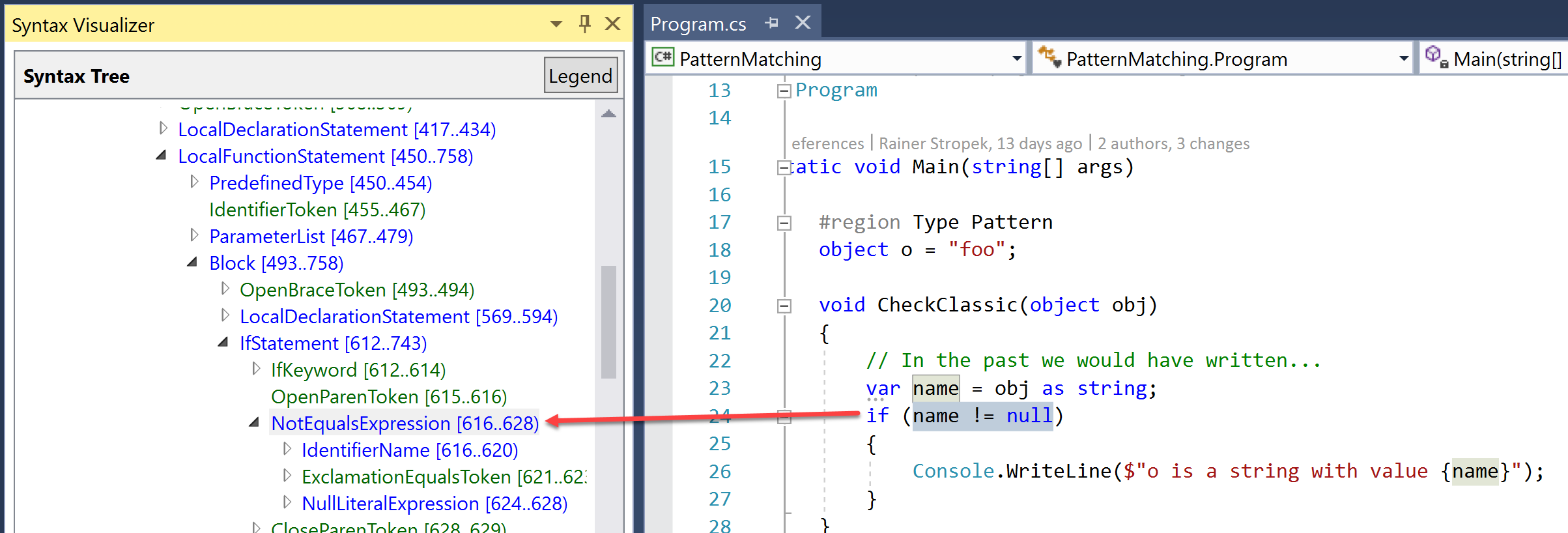
If we look at the syntax tree of the new version, we see that Roslyn has learned a completely new trick: The code leads to an IsPatternExpression, something brand new to C#.
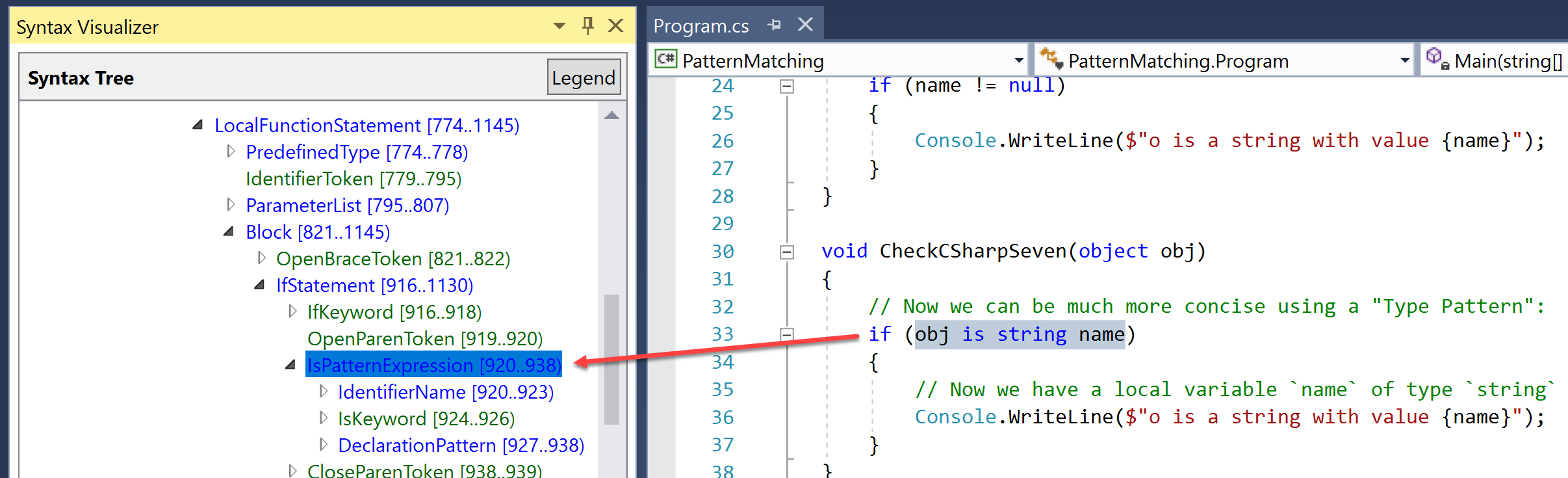
You wonder if there is a difference on IL-level? Yes, there is a slight difference as the following image shows.

I cannot present detailed statistics about performance of both variants on lots of different platforms and CPUs. However, I was curious and did some testing with both versions running in a tight loop for ten seconds on my own machine. In that test, the C# 7 version (CheckCSharpSeven) with pattern matching was between 2.5 and 2.7% faster than the classic version (CheckClassic).
Pattern Matching in switch
I encourage you to take a look at my complete Pattern Matching example on GitHub to see different syntax options that you get with C# 7. You will see that pattern matching also works in switch statements. Let’s take a closer look at one of these examples:
public static void SwitchWithPatternDemo()
{
object o = 42d;
switch (o)
{
case double d when d > 10:
Console.WriteLine("It's greater 10");
break;
case double d when d > 20:
Console.WriteLine("It's greater 20");
break;
}
}
The interesting point about this sample is that the value in o would fall into both case blocks. It is a double and it is greater than both 10 and 20. Will both case blocks get executed?
No, in such cases, the order of the case blocks matter.
Looking at the IL shows why.
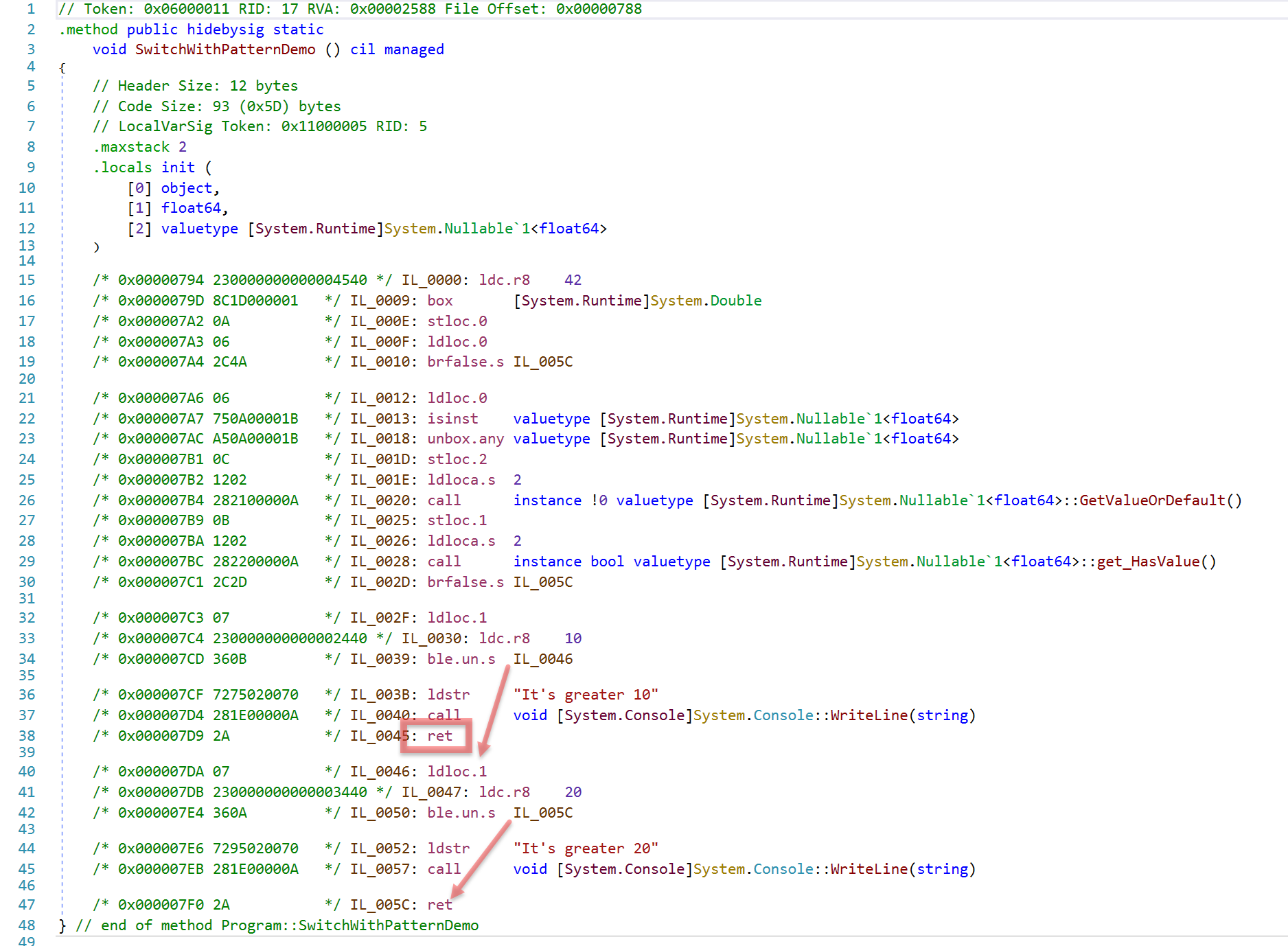
- Note that the type checking is only done once.
- If the first condition is met, the method will return (line 38) without doing the second check.
- If the first condition is not met, it jumps to the second check (line 34).
Tuples
The next feature I would like to take a closer look at, is the support for tuples. Tuples are nothing brand new in C#. .NET has the Tuple type for quite a while. However, only the advancements of C# 7 make tuples really interesting for everyday programming:
- .NET now has a tuple value type called
ValueTuple. This makes tuples with just a few basic types more efficient. - C# allows to assign names to the tuple’s items so you do not need to reference them with
Item1,Item2, etc. but with their semantic names.
Please look at my complete Tuple example on GitHub to see different syntax options that you get with C# 7. For the moment, let’s look at the following lines of C# code:
// Note that `Tuple` is a reference type
Tuple<int, int> AnalyzeWithTuple() => new Tuple<int, int>(numbers.Sum(), numbers.Count());
var oldTupleResult = AnalyzeWithTuple();
Console.WriteLine($"Sum: {oldTupleResult.Item1}, Count: {oldTupleResult.Item2}");
// ...
// Note that the following function returns a tuple
// with semantic names for each member.
(int sum, int count) Analyze() => (numbers.Sum(), numbers.Count());
var result = Analyze();
Console.WriteLine($"Sum: {result.sum}, Count: {result.count}");
Although we don’t see the value type ValueTuple in the code snippet above, it is used behind the scenes. The generated IL code reveals it:

So behind the scenes, C# 7 tuples are a combination of a new value type plus some syntactic sugar for giving names to the tuples’ members.
What happens if you compile a function returning a tuple in a class library? The user might not have the source code. How does the C# compiler still know about the semantic names of the tuple members? The solution is the attribute TupleElementNames that is compiler-generated.
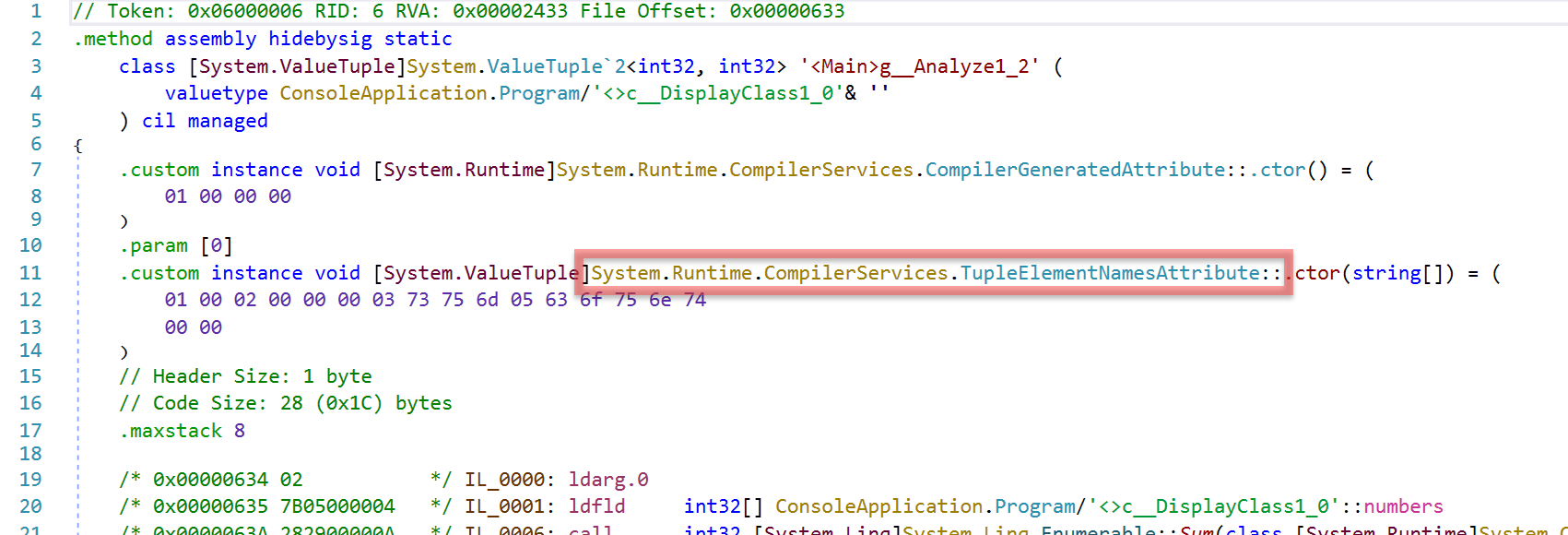
Note that the hex values shown in the TupleElementNames attribute contain the tuple’s element names sum and count.
ValueTask
The last feature I am going to talk about is ValueTask. In fact, the new C# 7 feature is not just about this specific new type. The innovation is that you can now write custom types other than Task that work with async/await. The feature is called generalized async return types.
ValueTask is a new type that takes advantage of it. Imagine a situation where you have an async function doing IO stuff with a caching function to enhance performance. Whenever there is a cache hit, you don’t need to do the IO. You can return the result immediately from the cache. In such situations, the overhead from allocating an instance of the reference type Task can become critical. As ValueTask is a struct, there is not need for allocating an object.
Let’s look at some sample code (larger example is on GitHub):
private static Task<int> GetResultTaskWithoutAwait(int index)
=> IsInCache(index) ? Task.FromResult(cache[index]) : LoadResultAsync(index);
static ValueTask<int> GetResultValueTaskWithoutAwait(int index)
=> IsInCache(index) ? new ValueTask<int>(cache[index]) : new ValueTask<int>(LoadResultAsync(index));
Both methods look quite similar. The main difference is the return type.
I ran both methods in a tight loop for 1,000,000 times and - guess what - the second version is a little bit faster. Does that mean you should forget about Task and always use ValueTask? Absolutely not!
You have to do careful performance tests to find out whether ValueTask is better in your situation.
In my little demo program, I compare different implementations (e.g. with/without async/await, with caching of Task results, etc.). In fact, in most cases, Task is faster than ValueTask. So be careful and only switch to ValueTask if you have measured performance advantages in real-world environments.
References
-
All the code snippets in this blog post are taken from a larger sample available on GitHub.
-
For performance analysis I use Microsoft’s awesome PerfView tool.
-
For disassembling managed code I use the great open-source tool dnSpy.
-
Microsoft has a great article about what’s new in C# 7. It also contains links to more detailed chapters in the C# documentation.
Content

Tags
.NET (40) ADC (1) Android (1) Angular (4) AngularJS (3) ASP.NET (7) ASPNET Core (1) ASPNET (1) Assembler (1) Azure (62) BASTA (2) Blazor (2) C# (35) C (1) CLI (2) Cloud (1) CoderDojo (1) Conferences and Workshops (2) Container (4) CPP (3) CSharp (5) DevOps (2) Docker (12) Documentation (1) DotNet (1) ECMAScript (1) GAB (1) HTML (2) HTML5 (2) Iron Python (1) JavaScript (3) JWT (1) Markdown (1) MEF (3) Microservices (3) Microsoft (2) Minecraft (2) Mobile (2) Node (1) Node.js (2) NPM (1) OData (5) Presentations (4) Project Management (2) Registry (1) Roslyn (2) Silverlight (3) Software Quality Days (1) SPA (1) SQL (3) SQLCE (1) SVG (1) TechDays (1) Techorama (1) Testing (1) TFS (9) time cockpit (4) TypeScript (18) Visual Studio (37) VSCode (1) VSTS (2) WebAssembly (2) Windows (1) WPF (9) Yarn (1)Authors
Related Posts
Techorama Belgium 2019 - Session Material
24 May 2019 - Docker, CSharp, Blazor, Angular, WebAssembly, Techorama
This year, I was again speaker at Techorama Belgium. I did a full-day workshop about Containers in Azure, one session about Angular, and one about Blazor. In this blog post I share the material and recordings of my talks.

Container on Azure and CSharp Spans at dotnet Cologne
Yesterday, I was at dotnet Cologne speaking about Container on Azure and Spans in CSharp. As every year, it was a great conference. Impressive, what community can do. In this post I publish links to the material I used in my sessions.

